What “Safe AI Deployment” Actually Requires
|
|
Category: Risk & Governance Author: Adam Clark Miller Publish date: 2026-04-07 |

Safe AI deployment is not a slogan. It is a design choice reflected in boundaries, permissions, fallback behavior, review paths, and clear ownership.
Safety must be designed, not merely described
The phrase “safe AI” appears everywhere now, often as a shorthand for general responsibility. In many cases, that language is well intentioned. The problem is that it is usually underspecified. It signals concern without making clear what has actually been designed to reduce risk.
That is not enough for a real operational environment.
If AI is being introduced into a workflow that affects decisions, data, customer interactions, approvals, reporting, or compliance, then safety cannot remain a broad aspiration. It has to be expressed concretely in the way the system behaves.
Safe deployment begins with scope
This begins with scope.
One of the most common mistakes in AI deployment is giving a system a role that is too open-ended for the surrounding controls. The system is expected to interpret broadly, act flexibly, and manage ambiguity without a clear operational frame. That may look ambitious, but it usually increases risk. The safer path is narrower: define the task, define the inputs, define the permitted outputs, and define what should happen when confidence is low or the situation falls outside expected conditions.
In other words, safe deployment starts with bounded responsibility.
A system that classifies inbound documents and routes uncertain cases to review is easier to govern than a system that is vaguely expected to “handle intake.” A system that drafts a recommendation for approval is safer than one that acts as an unreviewed decision-maker in a high-consequence context.
Permissions determine the level of risk
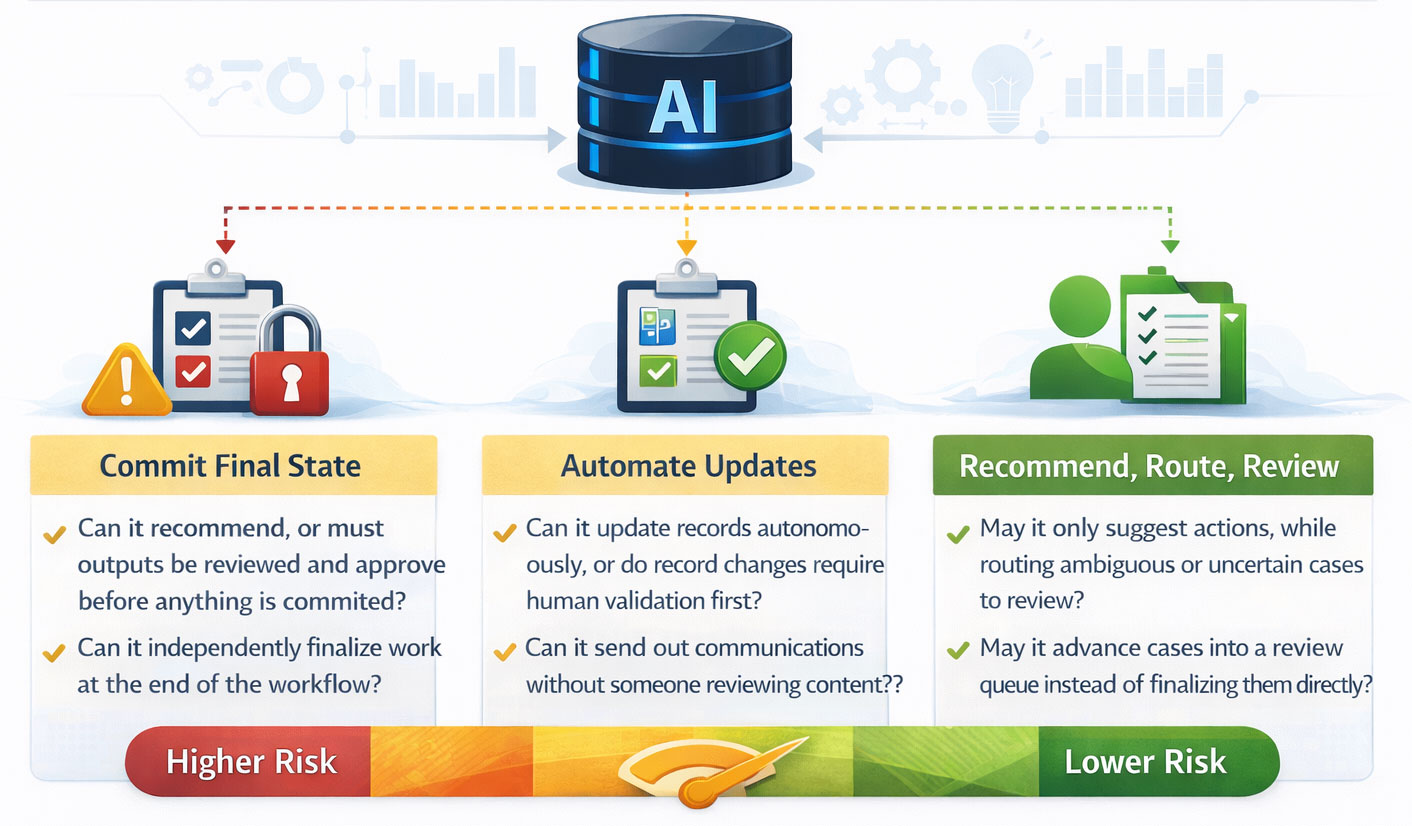
Permissions are part of that precision.
What is the system allowed to do?
- Can it recommend, or can it commit?
- Can it update records automatically?
- Can it trigger communications?
- Can it move work into a final state, or only into a review state?
These decisions matter because risk is not just about whether the model may be wrong. It is about what can happen when it is wrong.
Fallback behavior is a core safety mechanism
Fallback behavior is another essential element.
Every meaningful system needs a response for uncertainty, ambiguity, missing data, system degradation, and cases that do not fit expected patterns. Without fallback behavior, the organization is effectively relying on the AI to behave well all the time.
A safer system knows how to stop.
- It can defer.
- It can request review.
- It can ask for more information.
- It can route a case into a queue instead of forcing a decision.
- It can preserve the workflow even when the AI component is uncertain or unavailable.
Visibility matters as much as design
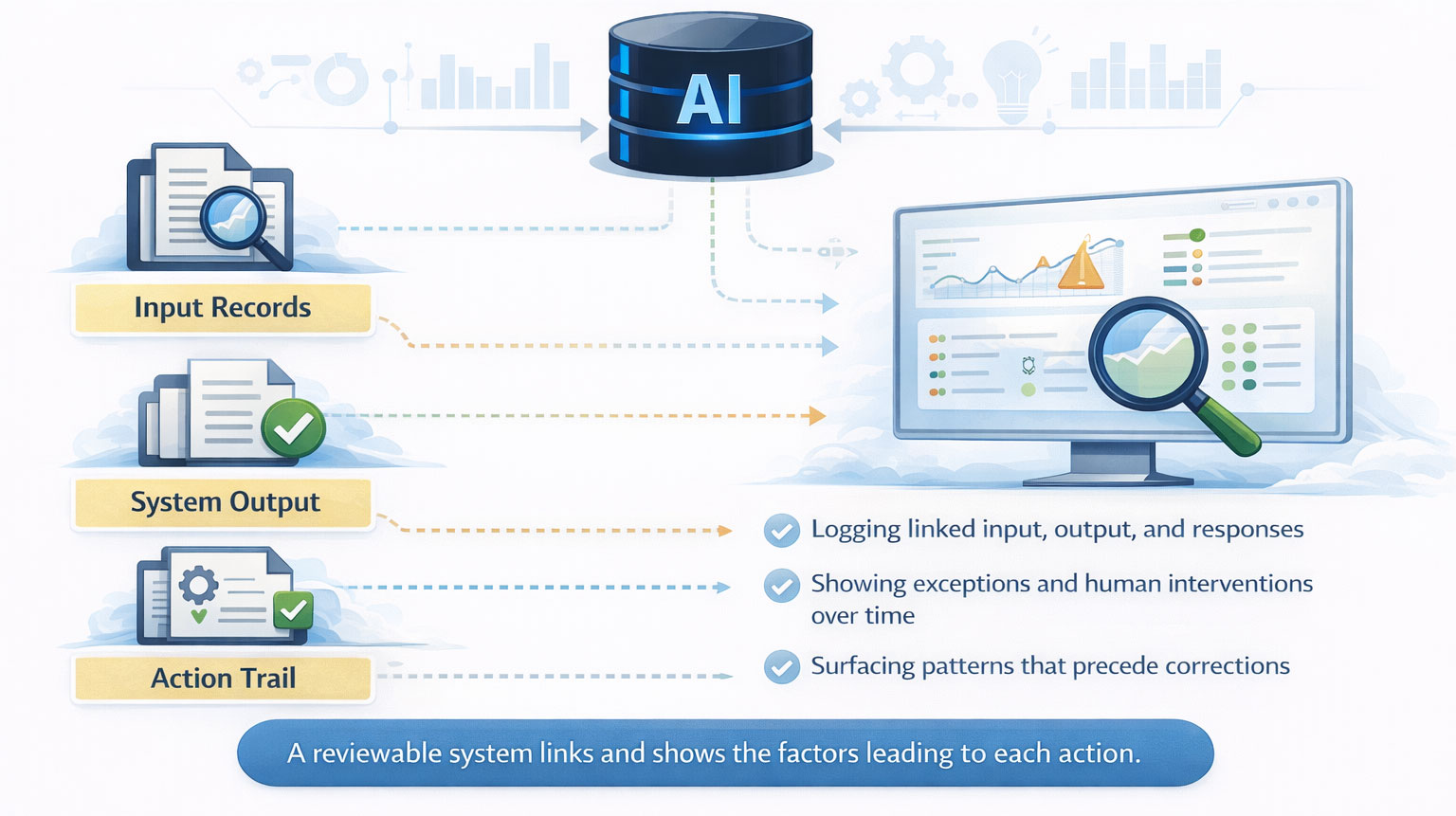
Logging and visibility are just as important. A safe deployment should make it possible to understand what the system received, what it produced, what action followed, and where human intervention occurred. Safety depends not only on initial design but on ongoing observability.
Testing is necessary, but not sufficient
This is one reason testing alone is not enough. Pre-launch testing matters, but no test environment fully reproduces live operations. The system also needs monitoring after launch.
That monitoring should not be limited to technical uptime. It should include behavioral signals.
- Are overrides increasing?
- Are certain exception types recurring?
- Are users bypassing the intended path?
- Are downstream corrections becoming common?
These patterns often reveal safety issues before they become larger failures.
Safe systems require ongoing ownership
Operational ownership matters too. Any system that meaningfully affects work needs an owner. Someone needs to be responsible for performance review, exception patterns, workflow changes, policy alignment, and escalation logic over time. Safety is not just a product of good implementation. It is a product of continued stewardship.
The goal is governable risk, not zero risk
The aim is not to remove all risk. The aim is to make risk proportionate, visible, governable, and contained.
Leaders should evaluate the deployment model itself
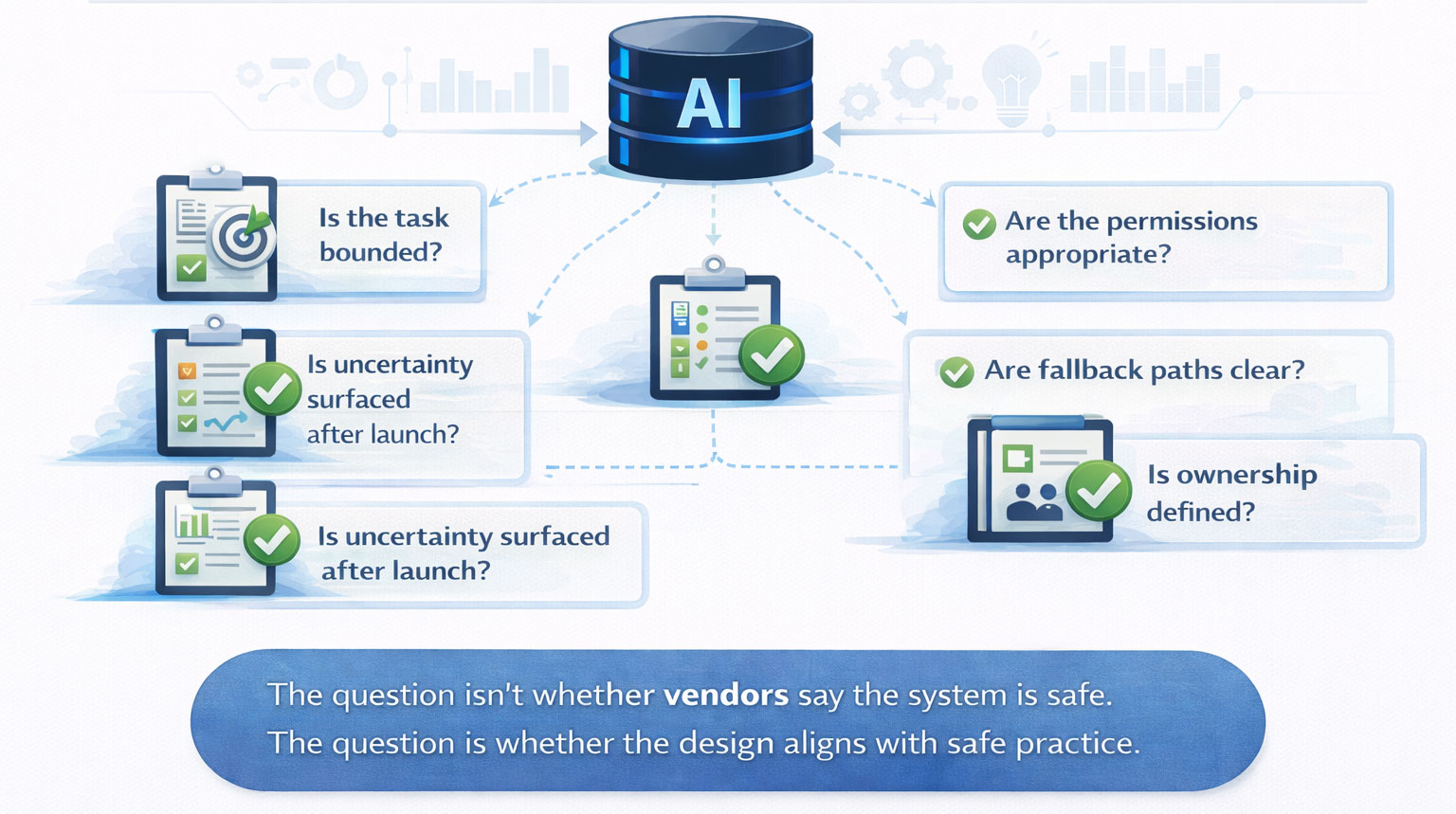
For leaders considering AI in operational settings, the practical question is not whether a vendor says the system is safe. The practical question is whether the deployment model reflects safety in its structure.
- Is the task bounded?
- Are the permissions appropriate?
- Are fallback paths clear?
- Is uncertainty surfaced rather than hidden?
- Can the workflow continue safely when the AI component is unsure?
- Is behavior observable after launch?
- Is ownership defined?
Safety belongs in the operating model from the start
If AI is entering a real business workflow, safety needs to be designed into the operating model from the beginning. Anything less is just language.
Share this article:
If your organization is facing real operational complexity and needs clarity before building, the next step is a Systems Discovery conversation.
All serious engagements with SongSwift begin there.
If your organization is facing real operational complexity and needs clarity before building, the next step is a Systems Discovery conversation.
All serious engagements with SongSwift begin there.